Multitwine: Multi-Object Compositing with Text and Layout Control
- CVPR 2025 Highlight -

Abstract
We introduce the first generative model capable of simultaneous multi-object compositing, guided by both text and layout. Our model allows for the addition of multiple objects within a scene, capturing a range of interactions from simple positional relations (e.g., "next to", "in front of") to complex actions requiring reposing (e.g., "hugging", "playing guitar"). When an interaction implies additional props, like `taking a selfie', our model autonomously generates these supporting objects. By jointly training for compositing and subject-driven generation, also known as customization, we achieve a more balanced integration of textual and visual inputs for text-driven object compositing. As a result, we obtain a versatile model with state-of-the-art performance in both tasks. We further present a data generation pipeline leveraging visual and language models to effortlessly synthesize multimodal, aligned training data.
Model Architecture
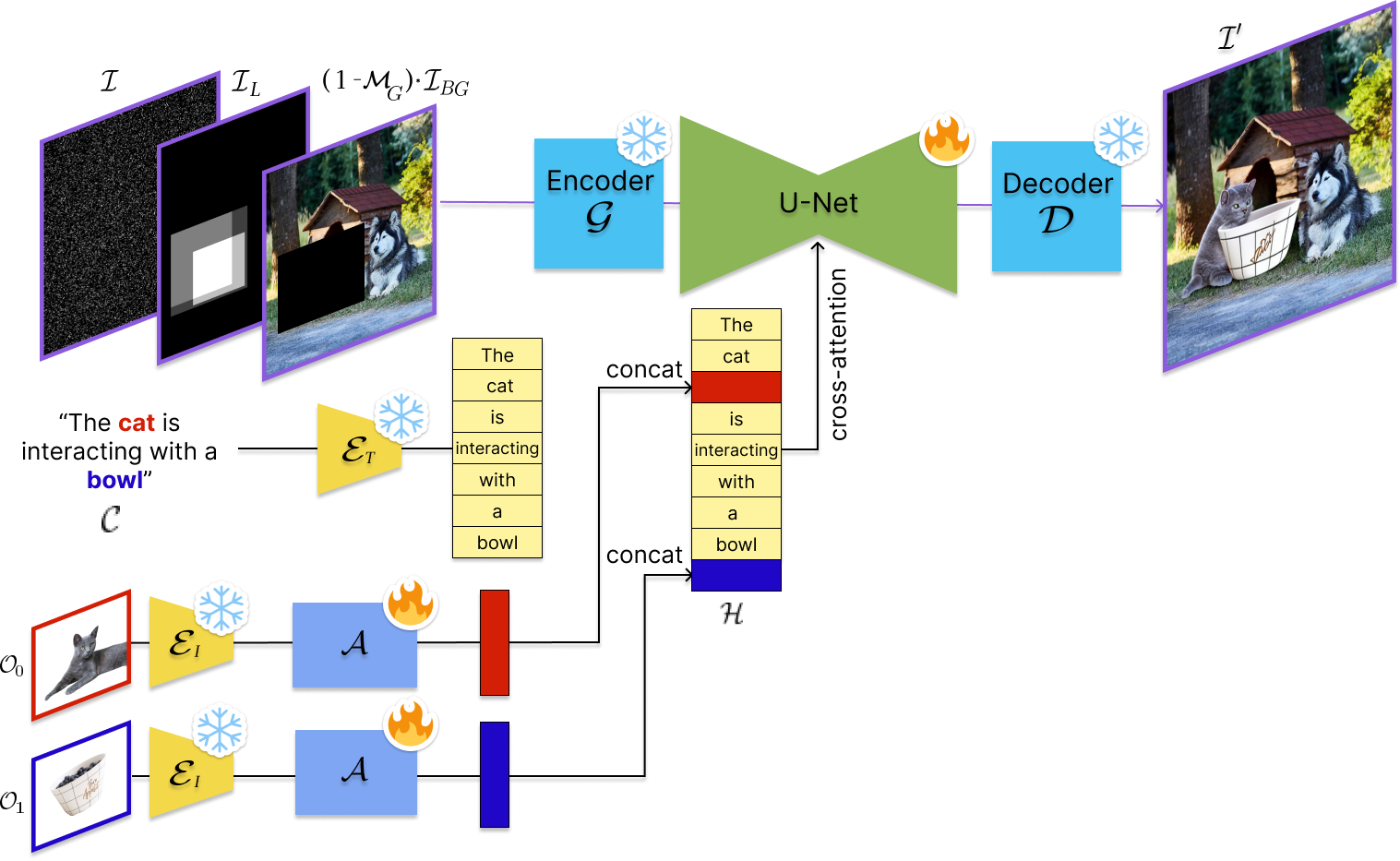
Our model consists of: (i) A Stable Diffusion backbone including a U-Net and an autoencoder (G, D); (ii) a text encoder (ET); (iii) an image encoder (EI); and (iv) an adaptor (A). Given a text prompt (C) and images of N objects (O0..N-1), the text embedding from (iii) is augmented by concatenating each image embedding after their corresponding text tokens. The resulting multimodal embedding (H) is fed to the U-Net via cross-attention. Masked background image ((1-MG)*IBG) and layout (IL) with object-specific bboxes are concatenated to input (I).
Comparison to Generative Object Compositing Models

We compare to recent generative object compositing models. These models support compositing from a single object, background, and bounding box, requiring sequential runs to add multiple objects individually. By compositing multiple objects simultaneously rather than sequentially, Multitwine displays multiple benefits: (i) it enables more cohesive harmonization and appearance consistency across objects and the scene (rows 1 - 5); (ii) it captures complex interactions involving object reposing with ease (rows 1, 6, 7); and (iii) with text guidance, the model can naturally complete scenes by adding any additional elements needed for realism (row 7).
Comparison to Customization Models

Our primary task is Object Compositing, but we also train for Subject-Driven Generation as an auxiliary task for achieving a better balance between text and image alignment in the compositing task. As a side effect, our model is also able to perform Multi-Entity Subject-Driven Generation, achieving comparable performance to state-of-the-art customization models.
Applications

Although not explicitly trained for them, our model exhibits some emerging capabilities.
Top Example (Multi-Object Generation): our model is able to perform multi-object compositing with more than two objects. By learning one-to-one object interactions, it develops a strong prior that allows it to generalize to compositing multiple objects simultaneously.
Bottom Example (Subject-Driven Inpainting): Our joint training on object compositing and customization enables the model to learn key subtasks, such as background synthesis, blending, harmonization, and reposing. These skills can be applied to subject-driven inpainting. In this task, the model uses text and layout guidance to seamlessly complete a scene, generating and integrating additional objects while maintaining a natural and coherent composition with the given visuals.